Data Science, Analytics & Statistics
"A problem well stated is a problem half solved." - John Dewey

Data Science & Database Administration
Through my work as a programmer, I have been tasked with a variety of challenging requirements related to data transfer, storage, analysis, management, and administration. I have also completed a professional certifications from HarvardX in Data Science, with individual certifications in probability, inference & modeling, linear regression, data wrangling, productivity, R, and machine learning, and earned a certificate for Epidemiology in Public Health Practice from Johns Hopkins University through Coursera.
I regularly employ SQL and R for big data analytics, visualization, and storage. Most of my professional work involves proprietary business data, financial and legal documentation, workforce efficiency systems, and product distribution systems. I also enjoy researching public health issues and actively work on several projects related to environmental science, finance, public health, and epidemiology as a private citizen researcher.
The following statistics dashboards demonstrate some of my past work using R and Shiny to conduct exploratory data analysis and machine learning related to various subjects of general public interest. These dashboards utilize various curated public repos, API's, R packages, and other known sources for data acquistion.
E-Books:
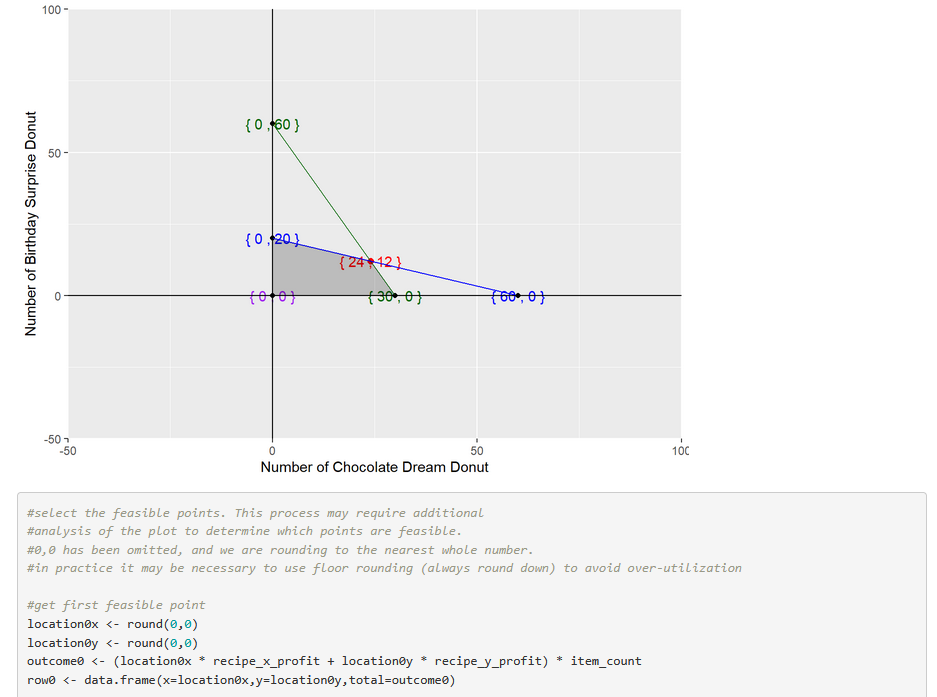
This e-book contains over 100 pages of R code, functions, commentary, and applied mathematics covering many subjects in finite math including matrix operations, financial formulas, combinations & permutations, set theory, number systems, and other fundamental subjects in the study of finite math. Applications include cryptography, trigonometry, and personal finance subjects, plus an in-depth look at some popular games of chance from betting on horse racing, playing poker and other casino games.
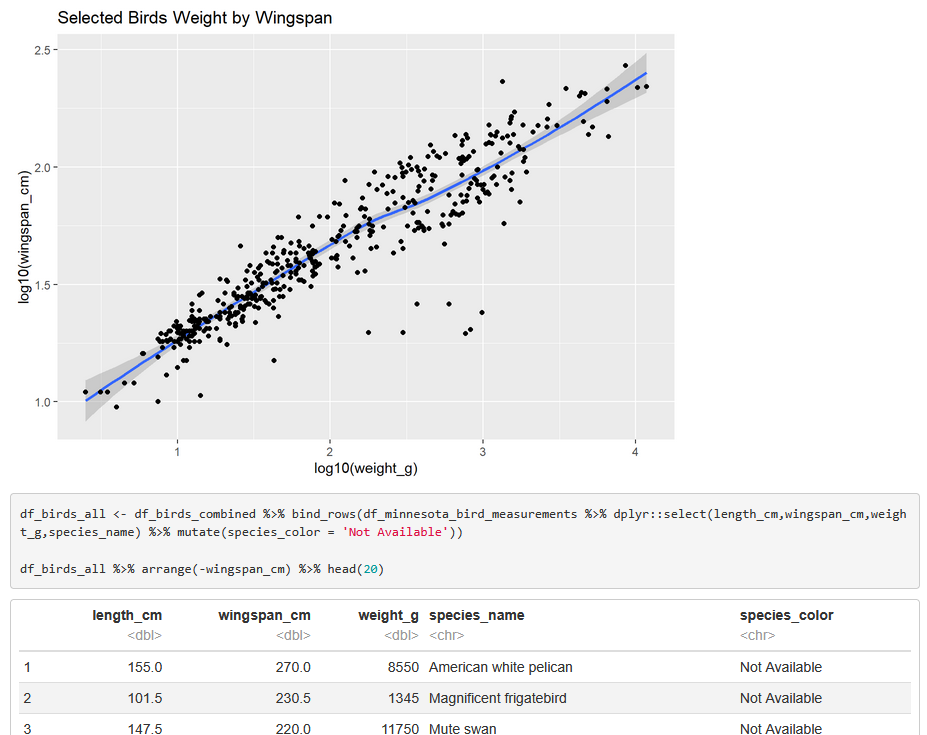
This e-book contains over 60 pages of R code, functions, commentary, and applied mathematics covering many subjects in statistics, probability, and data wrangling including how to categorize and classify data, create data tables & load external and internal data sources, and to calculate key statistics formulae including mean, meadian, standard deviation, and measures of dispersion. Applications include analyzing North American bird species trait data, Automotive data sets, and timeseries Highway safety data.
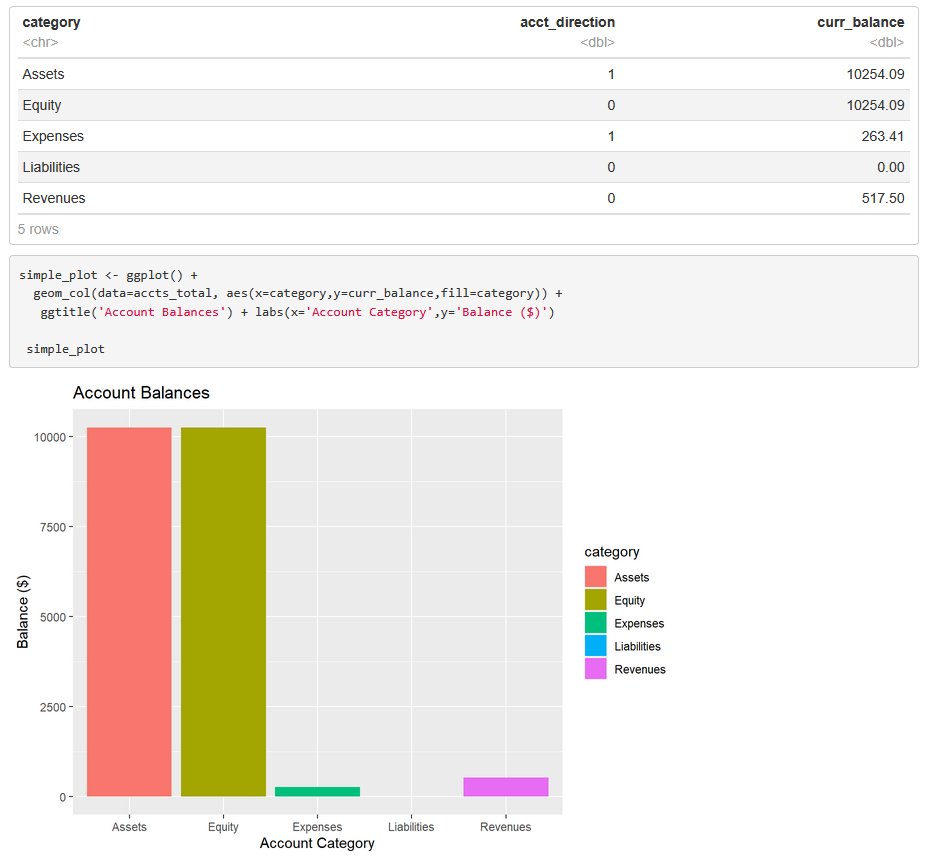
This e-book contains R code, functions, commentary, and methods to build a small business accounting system using R and RMarkdown. The guide covers subjects on how to organize a general ledger, cash flow statement, chart of accounts, and balance sheet using easy-to-understand R code and functions. The underlying database can be saved as excel files for simple, convenient data management for your small business. If you don't wish to use a subscription service for accounting, try R instead, and see how easy it can be to build your very own accounting system!
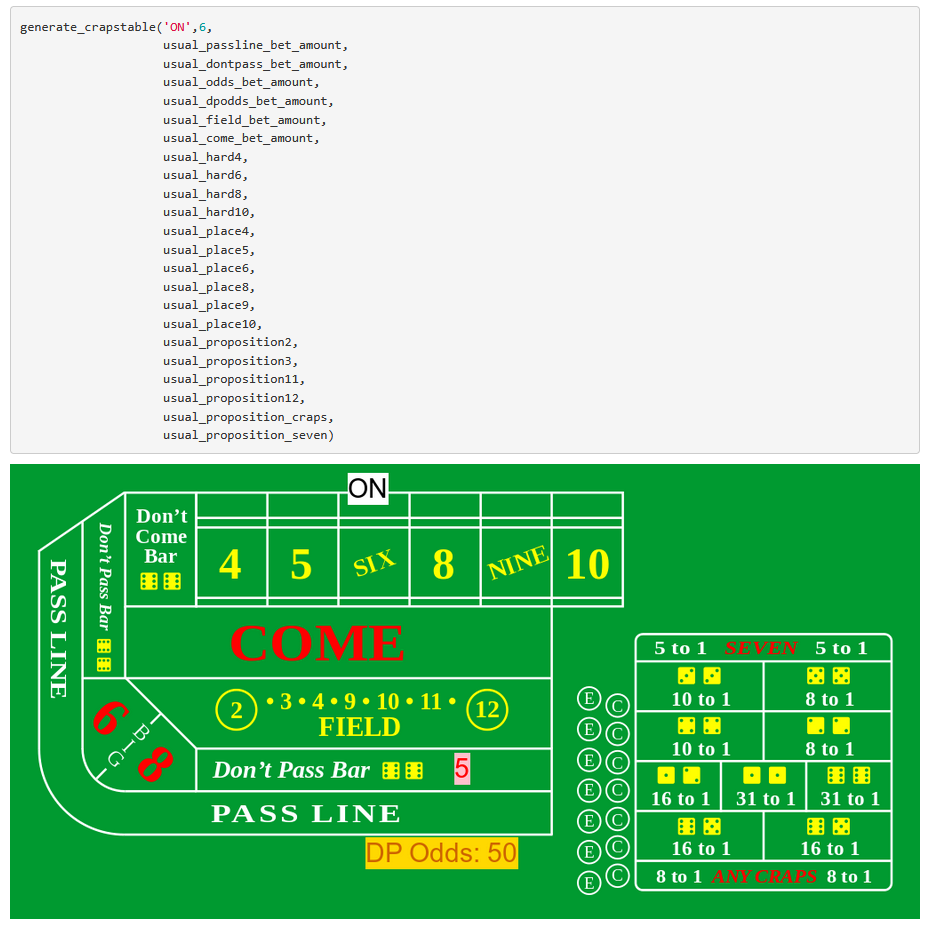
This e-book contains code and theory to understand the casino game of Craps, and to simulate the comlex rules of this game as they relate to bets, payouts, odds, and limits as the state of the game changes from the "coming out" or "off" state to the "on" state.
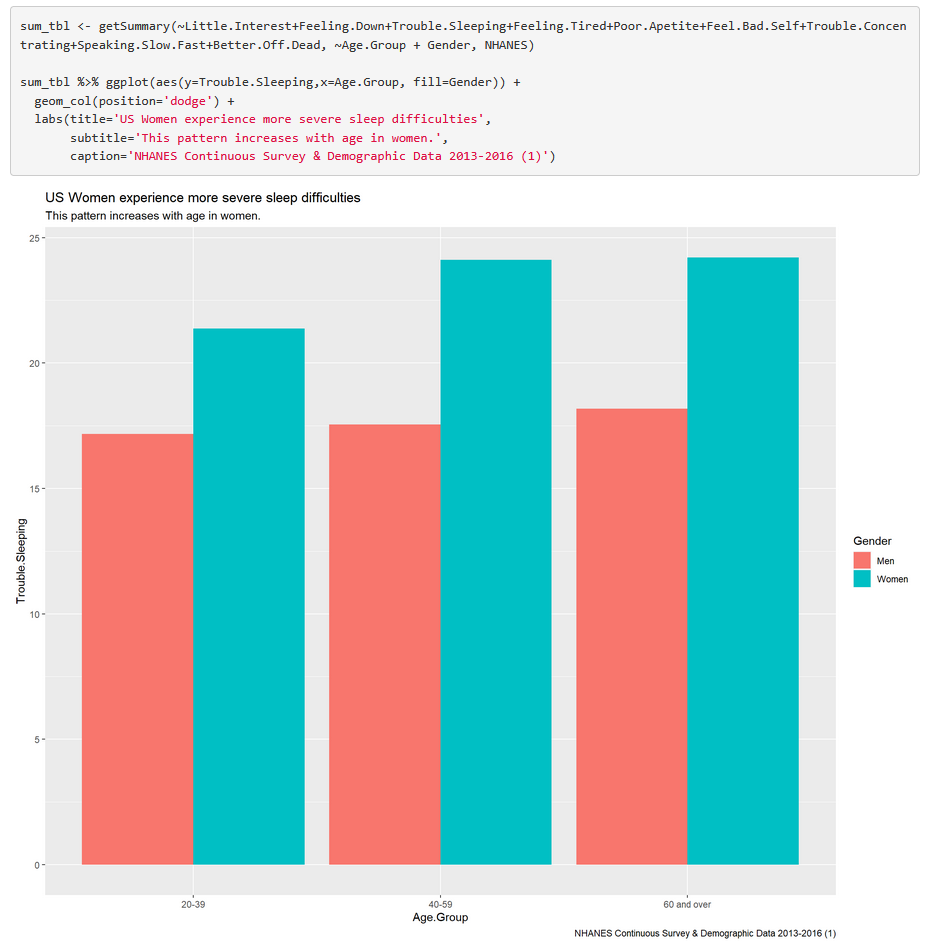
This e-book contains in-depth instruction on how to access the HNANES health survey to analyze data related to public health, collected and compiled by the National Institutes of Health.
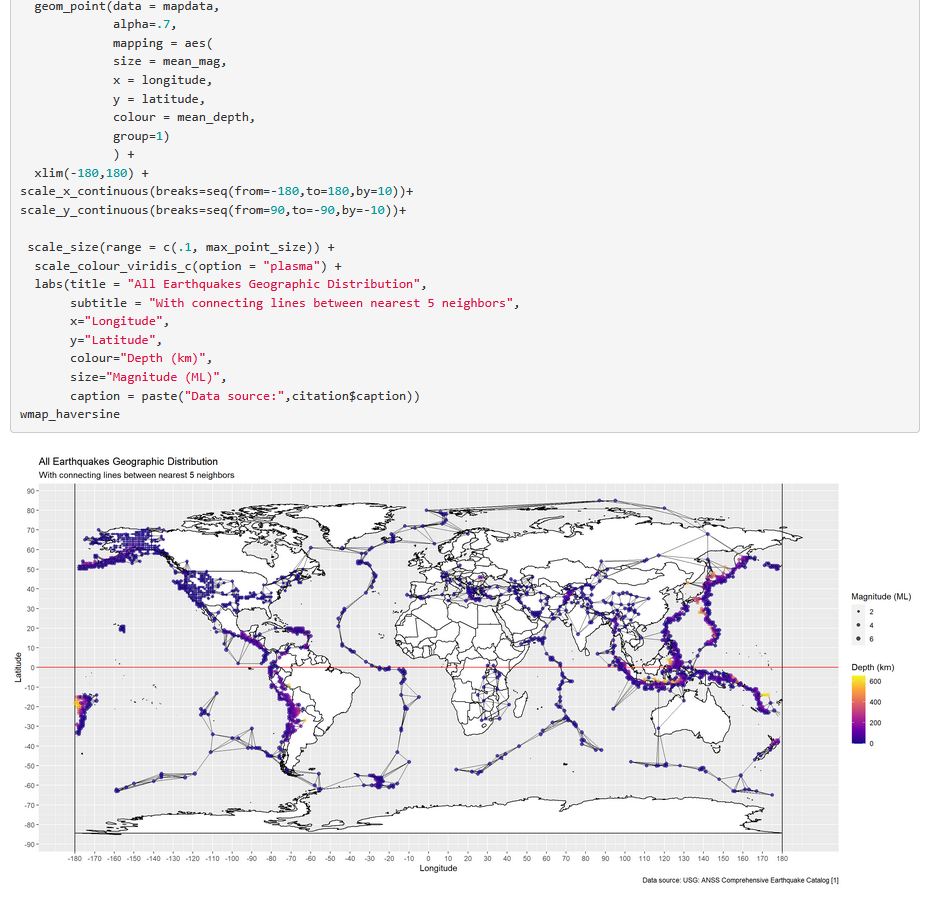
This e-book explores how to use data provided by the USGS to visualize and analyze earthquake events reported in real time by the United States Geological Survey (USGS). Projects include geospatial analysis, use of xpath to extract meta infopmration form a unstructured web page, using do.call and rbind over apply fucntions, big data application of great circle trigonometry including the haversine formula, subduction zone cross section analysis, development of animated plots using gganim, and use of the google maps API and ggmap.
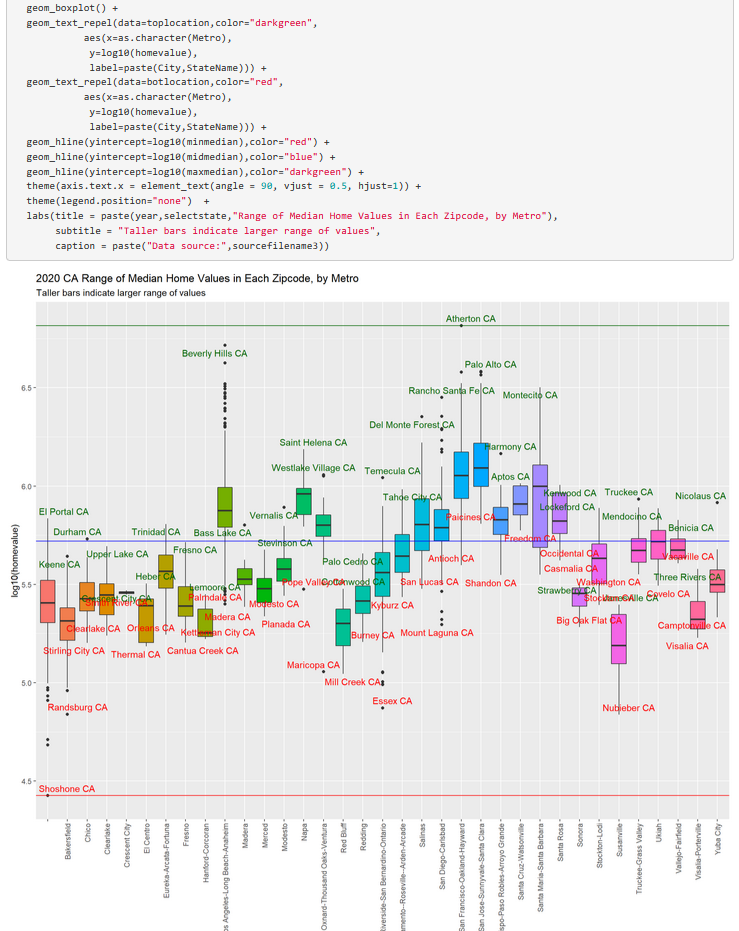
This e-book delves into the Zillow public data sets expresssed through the zillow home values index (zhvi). In this guide, we explore how to pull data frm this huge and valuable data source, target individual communities for analysis, and generate meaningful charts and graphs to track metrics related to home price, ownership, median value, change over time, rental rates and prices, and outliers in various categories related to home value and sales.
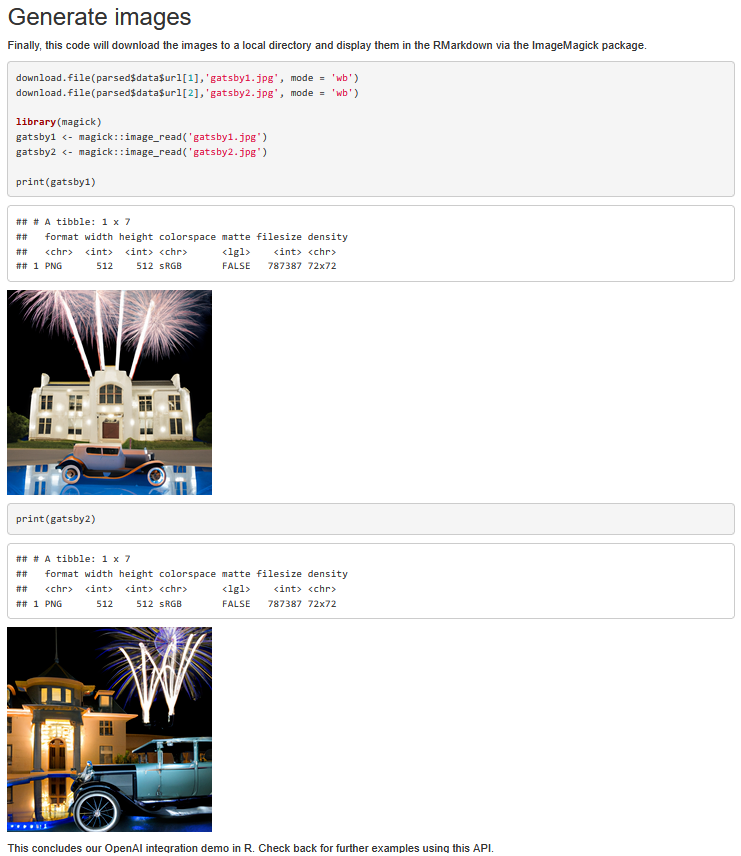
This project demonstrates how to build an OpenAI integration in R to get AI generated text and imagery for your R projects.
Note: Due to the use of many public, shared, and government provided datasets, these shiny dashboards frequently go offline and/or have issues with connecting to their data sources. This has been especially true since the current federal administration has aggresively targeted and systematically removed or limited access to scientific data. If you run into disconnection notices using one of my data vizualization dashboards, let me know and I will try to investigate and fix it.
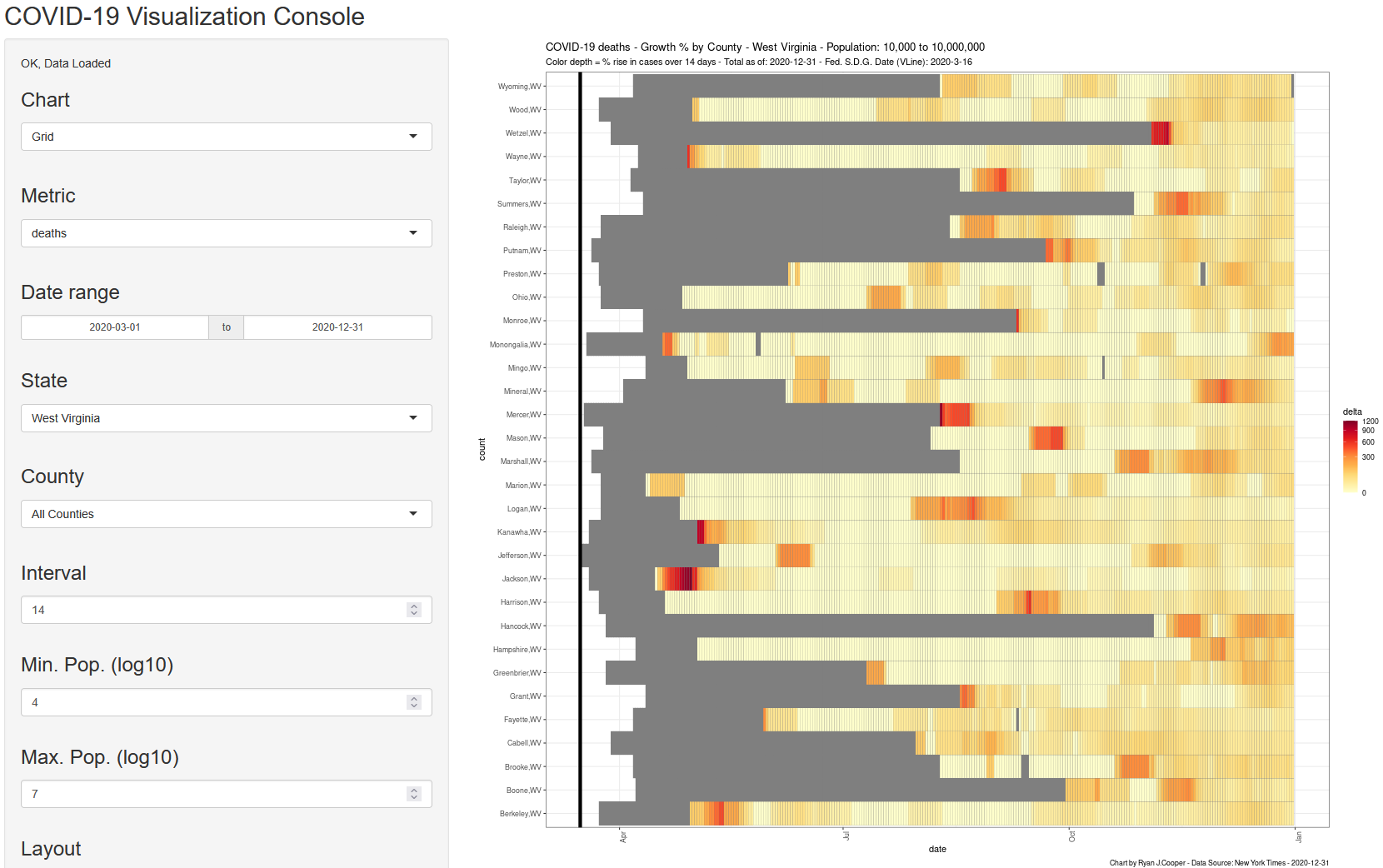
This dashboard shows Coronavirus stats and X day interval growth rates over bar, column and grid charts. It also offers colored chloropleth maps of the US by state, by county, and in individual state-level views. This tool incorporates data from the U.S. Census Bureau and COVID-19 stats from the NY Times.
This investment simulator helps you explore how dollar cost averaging (DCA) strategy combined with a home purchase would have impacted your expected net worth after a ten-plus year period from 2010 to present.
This visualization tool enables the user to browse and locate weather readings data from over 170 years of observations at thousands of US weather stations operated by the NOAA and made available through the National Climatic Data Center.
This mammal predictor app was built in connection with my HarvardX capstone in Data Science. In this project, I used heirarchical imputation strategies combined with a recursive random forest algorithm, which can use raw data on body mass, length, and other characteristics to predict the order, family and genus of a mammal with high accuracy.
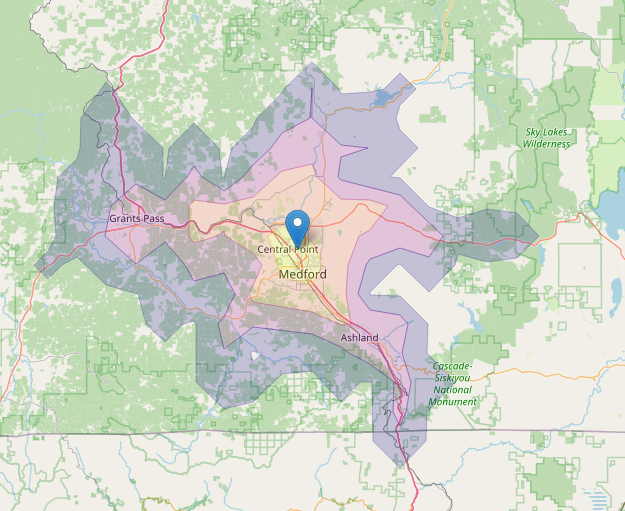
This dashboard plots drive times to Costco locations along the I5 corridor in Oregon.
- IMHE Data Visualization Dashboard
- US Census Data Visualizations
- CIA World Factbook
- NCDC Visualizations
- Corona Data Scraper
- Li Covid Atlas Project
Visualization & Graphics Developer Resources
Recommended Reading
- R for Data Science
- How Not to Be Wrong
- Storytelling with Data
- Numbers Don't Lie - Vaclav Smil
- EDA - Exploratory data analysis
- PSM - Problem Solving Methodology
- KI - Key Indicator
- KD - Key Determinants
- OI - Outcome Indicators
- Conceptual Framework - A picture of the problem that includes KD's
- Descriptive Epidemiology - Carefully frames statistical assertions in the form of a concise statement
- Person, Place, Time - The key considerations for a descriptive epi statement
- Proximal Determinants - Most causally linked to OI
- Distal Determinants - Less causally linked or non-modifyable determinants
- Ecological Fallacy - When inferences about the nature of individuals are deduced from inferences about the group to which those individuals belong
- Simpson's Paradox - When stratification reverses observed trends
- Leontief Model - A method of assessing the strength and balance of supply and demand in an economy
- Law of Large Numbers - As sample size grows, the mean of the sample apporaches the true mean
- System of Equations - A group of linear equations containing 2 or more variables with coefficients to be solved or optimized
- Identity Matrix - A square matrix matching the rows of matrix A with a diagonal line of 1's from the upper left to lower right, used to solve matrix problems
- De Morgan's Properties - Rules relating to how two or more sets interact by way of complements, unions, intersections, and exclusions
- Histogram - A visualization to show the quantity of records within a given rage of values within a dataset
- Boxplot - A visualization to show the interquartile range of discrete variables
- Scatterplot - A plot of paired variable points on an X / Y axis
- Venn Diagram - A visualization of the relationship of 2 or more sets resembling overlapping circles
- Heat Map - A visualization indicating quantitative values through use of coloring
- Choropleth - A visualization indicating quantitative values through use of coloring of pre-defined areas on a geographic map
- Isochrone - A visualization indicating distances in times on a geographic map
- Timeseries - Data whiuch provides observations in successive intervals
- Discrete Variables - Variables that exist independently of one another in a non-continuous fashion, eg. integers.
- Continuous Variables - Variables that exist in a continuous fashion, eg. floating point decimals.
- Ordinal Variables - Variables that have a natural or intrinsic order order, eg, A, B, C, D etc.
- Cardinal Variables - Variables that have a no natural or intrinsic order, eg. Dog, Cat, Giraffe
- CDF - Cumulative distribution function
- Bayes Theorem - Rules for determining conditional probability
- Chebychevs Theorem - Rules to determine probability of a random outcome
- Prisoners Dilemma - A paradox in decision analysis where individuals acting in self-interest do not produce the optimal outcome
- Fisher's Principle - An important law in evolutionary biology which explans the ratio of the sexes and the ESS
- ESS - Evolutionarily stable strategy, a refinement of the Nash equilibrium
- Correlation - A measure of how two variables move together
- Covariance - A measure of the joint variability of two random variables
- Bivariate Normal - When aX+bY has a normal distribution
- Decision Tree - A method of classification or prediction in which successive nodes split 2 ways based on a series of cutoffs
- RF - Random forests - an ensemble method utilizing decision trees and bagging
- PCA - Principal component analysis - a method of dimensionality reduction that defines an orthogonal coordinate system to describe variance
- LDA - Linear discriminant analysis - a method to find a linear combination of objects or classes
- ANOVA - Analysis of variance - a statistical hypothesis testing to characterize variance
- Imputation - The act of replacing missing data to improve a model's performance
- MAR - Missing at Random - when data is missing randomly, but missingness may follow a pattern in columns
- MCAR - Missing Completely at Random - when data is missing randomly with no discernable pattern
- MNAR - Missing Not at Random - when data is missing, and following a pattern of missingness
- Confusion Matrix - A set of numbers categorizing the outcome of a machine learning model in terms of True Positives, False Positives, True Negatives, and False Negatives
- Cauchy Distribution - A symmetric continuous probability distribution with heavy tails that matches better to data with significant outliers, such as daily stock market returns; Cauchy distribution is also known as the Lorentzian distribution in physics
- Systematic Risk - Risk to an asset which correlates closely to the risk to the entire market
- Idiosyncratic Risk - Risk to an asset which is specific to that asset and not correlated with general market risk
- Moral Hazard - The notion that having insurance may encourage risky behavior
- Selection Bias - The notion that those individuals who need insurance most will seek out that insurance, which increases the risk vs the risk applicable to the population at large
- Beta - The relationship between returns on an individual asset and returns in the overall market
- CAPM - Capital asset pricing model - all investors hold their optimal portfolio